
Permission to copy without fee all or part of this material is granted provided that copies are not made or distributed for direct commercial advantage, the ACM copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of ACM. To copy otherwise, or to republish, requires a fee and/or permission.CHI '96 Vancouver, B.C. Canada
(c) 1996 ACM
Images used herein copyright and other HTML pages (c) 1996 Stanford University
This is the linearized, most up-to-date version of this paper, which appears in the CHI'96 proceedings. The non-linearized version more suitable for viewing with a web browser can be found here.
A postscript version of this paper can be found here.
The substantially shorter paper version of this paper can be found here.
Web delivery imposes a novel set of constraints on user interface design. We outline the tradeoffs in this design space, motivate the choices necessary to deliver an application, and detail the lessons learned in the process.
These issues are crucial because the growing popularity of the web guarantees that software delivery over the web will become ever more wide-spread.
This application is publicly available at: http://www-ksl-svc.stanford.edu:5915/
For example, an ontology about physical measurement [5] defines logical relations and functions that specify concepts such as unit of measure (e.g., meters), physical dimension (e.g., length), and algebraic operators for unit conversion and dimensional analysis. Such ontologies are used to enable the sharing and exchange of data and models among distributed and heterogeneous applications.
Ontology construction is, by nature, a distributed, collaborative activity [7]. Since an ontology is a specification of a domain that is common to several applications, defining an ontology is analogous to defining a technical standard where effective communication and collaboration is required. Not only must there be some medium for forming concensus on the meaning of terms, but the expertise needed to define and review ontologies is distributed. For example, an ontology of therapeutic drugs is the product of a concensus among practitioners in the field and other potential stakeholders - all of whom are distributed across geographical and organizational boundaries (e.g., hospitals, insurers, government agencies). These properties of the user population motivate the development of distributed collaboration and the ontology editor tool.
Our application is unusual among web services because it allows users to create and edit objects, rather than simply retrieve them by following hypertext links or by making simple database queries.
The implemented application provides a full, distributed, collaborative editing environment with over a hundred user commands, context sensitive help [14], context sensitive user feedback and bug-report collection, multi-level undo/redo, multi-user sessions. It has been publicly available since February 1995 and (as of 1/96) supports about 900 users, about 150 of whom we would classify as "serious," who average over 2000 requests per day. Feedback from users and data collected online support the claim that it is possible to deploy richly interactive applications over the web. Based on our experience in developing the ontology editor, we offer an approach to developing and delivering web-based applications that instantiates this claim.
The web appeared to be a reasonable alternative. We had previously developed experience in providing automatically generated HTML documents to describe ontologies and other structured objects [9]. People found that using their native hypertext browsing systems to examine these documents was both valuable and appealing.
The ontology editor is a good candidate for this approach because (1) it requires distributed access from heterogeneous environments; and (2) think-time dominates computation time. This makes it possible to provide a useful shared computational resource for a community of users from a centralized server without the hardware costs being too onerous.
From the outset, we wanted to make our potential user community as large as possible. The target community is diverse and includes academics, industrial researchers, and government employees. Once we had established our web-based system, our user community grew from a handful to hundreds in the space of a few months.
Our burgeoning user community was an additional incentive to use the web. Furthermore, distributed access eliminates the need for our users to have high-end hardware systems or expensive licenses for the proprietary software systems that we used to develop our application more efficiently. A centralized server model also means that we can make changes and upgrades to the server at a single site (or small number of controlled sites); the new, improved software is instantly accessible to all users. In short, we decided that it would be cheaper to provide free computational resources to our entire user community than to develop shrink-wrap software and distribute it to them.
Our challenge was to design a user interface that operates under the constraints of the web, remains intuitive and natural to users, and provides full access to the application.
HTML used for documentation: Our application has no manual at all per se. All documentation is provided on-line using the same browser that the user already employs to operate the application.
Guided tour: One important aspect of the documentation is a guided tour [11, 15], which takes the new user through a credible editing scenario, motivating the different features of the system.
In-context, automatically-generated help: Unlike applications such as Microsoft Word 6.0, in which documentation is available only in an idiosyncratic hypertext browser, our application uses the same hypertext browser uniformly for all of its interface. This means that help and documentation are seamlessly integrated with the rest of the system. Indeed, the help facility builds help pages in real-time so as to give the most focused and helpful response in the user's context. A novel feature of the help facility is that the commands available to the user are echoed as widgets on the help page (figure 1 right). If the user clicks on the widget in the help page which has accompanying explanatory text and links to worked examples, then the command associated with that widget is activated just as if it were invoked on the page from which the user made the help request.
Familiar interface: There was no existing interface metaphor for ontology editing. We selected a document metaphor (as opposed to a two dimensional representation as a directed graph, for example) so that the application could be smoothly integrated into the HTML world. This allows users who are familiar with hypertext documents and browsers to make an easy transition into our interactive application.
There are a number of possible ways to deliver applications to a user community. In the past, we had always built our software to be as portable as possible, testing it on a number of platforms and with a number of different compilers from different vendors. This approach was necessary because our user community always wanted us to ship source code to them so that they could modify and experiment with our software. The cost of testing and ensuring cross-platform portability proved to be very high. Users would often employ versions of operating systems, platforms or compilers to which we had no access. One way to address this problem would have been to offer only shrink-wrap software releases to our users. This was not a tenable option because of the diversity of platforms in our user community. We simply could not build a "PC-only", or "SUN/OS-only" application. Our new approach of keeping control of the software, and shipping a network service seemed the best way for us to overcome the difficulties of shipping software, while being able to impact a wide user community.
Figure 1. The final design (left) used a row of icons (top) for important or frequently used operations, and pop-up menus preceded by submit buttons (e.g., "File" top left) as labels. Selecting the `?' help command (top center left) takes the user to a page explaining all applicable commands, and with a labeled explanation of the page (right). The command widgets on the help page are real. Selecting one of these widgets will execute the command in the context of the page that the user was on. Tears in the figure elide material extraneous to this discussion. Note: this figure is very wide and might require horizontal scrolling to see the right-hand part of the figure. A slide show examplifying the Help feature can be found here.
The only way for the server to transmit information to a browser is in response to a submit or select action initiated by the user. Moreover, there is a fundamental difference between the type of interaction supported by HTML and the forms of interaction with which we are all accustomed in graphical user interfaces. In GUIs, operations typically take the form of the user selecting an operand or operands through direct manipulation and then applying an operator by means of a menu selection or keyboard accelerator. In HTML-based user interfaces, there is no notion of selecting objects pre se. There are, in effect, two disjoint forms of interaction:
Consequently, it is currently impossible to implement many features of sophisticated user interfaces over the web. In particular, tightly coupled interfaces that provide immediate feedback to the user are not possible. For instance, given an initial menu selection, it is not possible for the application to gray out options that are incompatible with it. Furthermore, there can be no direct manipulation of objects such as one might find in a graphical class browser. Finally, it is not possible for the application to preempt the browser's activity or provide any asynchronous communication. For example, it is not possible to notify the user asynchronously about the results of a background task or remind the user to save work.
Delivering notifications of collaborators' work on shared data is another problem. Since several people simultaneously edit the same ontology, we need to provide some way for users to be made aware of the changes made by others. Today's HTTP makes this difficult because it does not allow a server to send unsolicited notifications to the client. We work around this limitation by presenting pending notifications at the top of the page in a dialog. The notification includes a textual description of the changes being made by collaborators on shared data, and a link is provided that will take the user to the modified object. Within a shared session, users share the same undo history so that a user can undo damage performed by a less enlightened user. A command is also provided to make announcements to users so that they can be forewarned of a change to come and be given a suitable justification. An improvement to the HTTP standard to accommodate asynchronous notifications would be preferred (some are being proposed).
Bandwidth is a key constraint. Each user action (submit or select) causes an entire new page to be transmitted back to the browser over the network. There is no method for the application to cause an incremental update of a portion of the display. Even on high-bandwidth local area networks, transmitting and rendering large pages is time consuming; for distant browsers it becomes the dominant cost.
The application has very little control over appearance. HTML explicitly cedes rendering decisions to browsers. This has many advantages for browsing hypertext documents, but it proves awkward for interface design. There is little control over the location of displayed objects on the finally rendered page. In particular, if a page is too large to fit on a single screen, there is no way of controlling how and to where the browser will scroll the page. This registration problem can be very difficult to work around and frustrating for users (see section 3.4).
The widget set available through HTML's forms capability is extremely restricted. It includes only pop-up menus, single/multiple selection scrolling lists, submit buttons, checkboxes, radio buttons, mapped images, and text type-in widgets (see figures 1 and 2). There is no way to combine either submit button or anchor behavior with a pop-up menu to provide the sort of command selection model that is present in so many user interfaces (e.g., the Macintosh menu bar). There is no way to associate a "right button" menu with items, nor is there a way to provide constraints on selection elements (e.g., toggling "show text files" causes a scrolling list of files to filter out non-text files). There is also no way to include iconic elements in menus or scrollable lists. (See here for a comparison of the widget set under different platforms)

Figure 2. In early designs, radio buttons were used to select an argument (left). Selecting an operation from a pop-up menu and clicking on a submit button (top left) inserted suitable edit widgets into the flow of the page at the selected location (right). A slide show of the actual mockup HTML pages can be found here.
The desire to minimize the number of clicks and intermediate pages has some consequences. Because we want to minimize the number of clicks that a user performs, we are inclined to make pages richer (and potentially more confusing) to a user. Our application consists of the display and editing of a hierarchy of objects; classes exist within ontologies, classes have slots (attributes), and those slots can themselves have facets (attributes of attributes). We could have chosen to present a different page for each slot and for each facet in any given class. Instead, we display all of the slots and facets of a class on a single page. A user can therefore edit a facet value directly on a class without going through any intermediate pages. This design helps to satisfy our goal of minimizing the number of clicks and intermediate pages, but at the expense of making the pages larger and more complex. The user is presented with considerably more information than may be of interest, and the user is more likely to have to scroll in order to see what is of interest.
We explicitly decided to support multiple browsers. Some user interfaces on the web are almost unusable without using Netscape. We did not want to limit our user community in this way, and so preserved a consistent look and feel across platforms and browsers.
In contrast, we chose to use the native window system's submit buttons for our interface. Our application was going to be complex enough without the user having to relearn what a button is supposed to look like.
The constraint of supporting naïve users meant that we could not allow any user interface tricks such as having extremely stylized icons that cause differing behavior depending on where on the icon the user clicks. While such approaches allow very terse and dense displays that efficiently take advantage of the available screen real-estate and bandwidth, they would be difficult for members of our target community to understand and learn.
We tried several different approaches to provide the functionality of a right button command menu, which is not supported by HTML. For example, in one mockup, there was a radio button in front of each editable object, and at the top of the page was a pop-up menu of operations to be applied to the object selected with the radio button (figure 2). A "Do It" submit button caused the execution of the selected operation. This method requires three different widget selections which involved mouse travel from the selected object back to the top of the page and often required the user to scroll the viewport. This would have been burdensome on our users.
We addressed this problem by using a single intermediate page for edit operations, and by limiting the expressiveness of the user interface - we do not allow the user to execute all conceivably legal operations at any given point. We eventually settled on a design in which a small edit widget would be placed next to any editable object. Selecting this widget would take the user to a page just like the current page, only with suitable edit widgets replacing the value that was selected, and allowing the user to select between a number of possible edit options.
In our application, it is necessary to be able both to create new objects (e.g., classes) and also to add objects to existing objects (e.g., add a property or value to a given object). Finding a good way to represent this proved tricky, and we experimented with several methods. For example, we tried using a "dummy" entry for values, so that for every list of values there would be an extra one at the beginning (or end) in italics that was a place holder for a new value to be added (this is an example of this design mockup). This was found to be confusing, and was soon dropped in favor of the design described in the next section.
The next problem that arose was that users were confused by the methods for creating and adding objects and values. They often added values that were illegal or non-existent objects. The number of possible legal values for attributes in the system is typically too large to enumerate explicitly. Because of this, we developed a sophisticated, context-dependent completion facility, which space prevents us from describing here.
After a few iterations we ended up with a design which we have broadly kept since this early stage (see figure 3). In this design, we distinguish between five different types of widget:
 pencil icons that allow the user to edit an existing value and addition
widgets, which are represented by icons such as
pencil icons that allow the user to edit an existing value and addition
widgets, which are represented by icons such as  .
Only one type of object can be added at each location; the type is indicated
by the icon.
.
Only one type of object can be added at each location; the type is indicated
by the icon.

Figure 3. The final version uses edit widgets in front of all editable objects, and "+" widgets wherever an addition is possible (left). In this example, we show editing the Slot-Value-Type facet value of Thesis.University from Institution to University. Selecting an edit pencil inserts the necessary widgets to elicit or modify the value in context (middle). The user has entered University instead of Institution. The user can remove screen clutter by inhibiting all edit widgets (right). Here is a detailed worked example of an editing session using the ontology editor, showing a number of the features of the editor.
Although we went to considerable effort to make the user interface clear and intuitive, it was still novel in many ways. To familiarize new users with the meaning of the various icons and edit widgets they might see, we introduced a "Welcome" page which displays the icon images together with a brief explanation. Users can suppress this page once they are familiar with its contents.
By this point, we were able to edit values and create new objects in our system, but we were unable to save our changes. Our user interface mockups had focused exclusively on the different ways to edit objects in the system - they completely neglected the sorts of operations that are typically found on the "File" menu of a normal user interface. This presented us with a problem. We already had a row of buttons at the top of the page that would provoke the creation of new objects. When we added the options that were necessary for typical file menu operations we found that we had a glut of buttons. The number of buttons would only increase as the system became more sophisticated.
At this point, we had to make a significant compromise. Again, because HTML does not support pop-up submit buttons, we were unable to implement the obvious and familiar behavior of a menu bar. The only "correct" model for command menus in HTML is the exhaustive enumeration of the commands as submit buttons. This was untenable because of the number of commands we needed to support (typically around 40 per page). As an alternative, we partitioned the commands into broad classes and put the commands on menus. In front of each menu we placed the name of the menu as a submit button (see figure 1, top left). This meant that the user had to select an option from the menu and then click on the submit button to execute the selected operation. This is non-standard, but we found that our users got used to it fairly quickly, probably because we went to significant effort to make sure that the system would always put the most likely choice as the default option on the menu. Thus, a single pointer operation often suffices.
Because we could not predict whether our users would find the factoring of commands onto menus with submit buttons described above reasonable, we introduced a user preferences mechanism that allowed the user to control, among other things, the look and feel of these menu commands. In practice, most users ended up accepting our default setting for the command menu's look and feel. The desire for menu flexibility was the impetus for us to introduce a user preferences facility, but this feature has become ever more important in our system. Users connect to our application from all around the world from sites with widely differing quality of network connectivity. Consequently it is very important to support options that let the user trade prettiness or verbosity for bandwidth.
The issue of how much power to give to the user came up with the introduction of this command menu model. Our system is non-modal in the sense that it is always theoretically legal to jump to (say) a class creation dialog from the middle of a different object creation dialog. By default, we choose to hide this fact from users in order to simplify the appearance of the user interface. However, power users resent such restrictions, and so we have had to add extra preferences to allow our power users full access to all applicable commands, irrespective of their current context.

Figure 4. The hierarchical class browser shows large graphs of objects in a compact form. Triangular widgets open and close subgraphs. "Focus" widgets move the selected object to the root of the displayed tree.
We found that however hard we might try, our application always produced pages that were multiple screens in height. Consequently, we replicated the menu bar at the bottom of the page so that the user could scroll to the nearest end of the document in order to select one of these more global commands.
User feedback has caused us to spend more effort on displaying large ontologies. We have recently addressed this by factoring pages showing large ontologies automatically. We have also introduced a method of focusing the hierarchical browsing tool onto subgraphs of the class lattice, and for using this same hierarchical browsing technique to look at attributes as well as classes and instances.
Another problem with the edit-in-place model of interaction is that HTML and HTTP give no effective control over viewport positioning. This means that when the user selects an edit operation, we have no choice but to refresh the whole page (unlike a more tightly-coupled user interface in which the system might push existing text aside in order to make room for the edit widgets). Although it is possible to tell the browser where to scroll to on the new page, this is very coarse-grained control. Browsers differ significantly in their scrolling behavior, and this typically results in a loss of registration of the user's viewport, and therefore the loss of the user's cognitive focus.
In practice we suspect that it might be better not to use this edit-in-place model, but rather to use simple pages that give the illusion of modal dialogs. This is an open design question and needs further investigation. Registration of the display is only reliable when the whole HTML page is less than one screen in height. Because browsers cannot inform the server of the browser's window size or exact viewport position within a document, this problem cannot be solved in general. Furthermore, our application typically generates HTML pages more than one screen high.
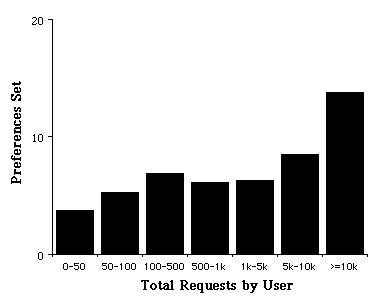
Figure 5. The average number of preference variables set by each user plotted against the total number of non-trivial requests made by each user to our server
If we look at the actual preferences that are being set, we see that a
number of the selections clearly represent a particular user's personal
preference for some particular look and feel, other preference selections are
clustered around, for example, a number of preferences that allow the user to
control the bandwidth used in communicating with our server. Indeed, we have
found that the issue of bandwidth is sufficiently important to our users that we
label any preference that might impact bandwidth with a  splash
graphic.
splash
graphic.
Please note that although in this section we refer to Java, the reader should treat this as a generic reference for some facility that allows the portable specification of client-side applets. At present, it would appear that Java will win this war, but this is by no means certain.
<A HREF="some-default.html"
ALTERNATIVES="red.html",
"green.html",
"blue.html"
ALTERNATIVE-PRINTED=
"Red",
"Green",
"Blue">
Color
</A>
<INPUT NAME="My Button"
TYPE="URL"
VALUE="URL-for-my-button.html">
<INPUT TYPE="submit" NAME="My Button"
VALUE="my-button"
ACTION="/cgi-bin/foo#scroll-to-here">
<INPUT TYPE="SUBMIT"
NAME="My Button"
VALUE="my-button"
ACTION="#scroll-to-here">
Scroll-position: <<name>>[+/-<<lines>>]
Scroll-to: <<name>>[+/-<<lines>>]
<TEXTAREA NAME="my-textarea"
scrollbarpositions=<<positions>>>
....
</TEXTAREA>
<<positions>> ::= <<position>> |
<<position>>, <<positions>>
<<position>>::= [vertical|horizontal]
= [left|right|top|
bottom|none]
<INPUT TYPE="submit"
LOCATION="menubar"
MENU="Ontology Editor|Create"
NAME="Class"
VALUE="create-class">
Clearly, one would want this facility to support the TYPE=URL attribute option mentioned above as well.
<A HREF="item-1235897" DOCUMENTATION="Edit Class">
<INPUT TYPE="SUBMIT"
DOCUMENTATION="Delete this class and all of its subclasses"
NAME="Delete">
<SELECT.....>
<OPTION DOCUMENTATION="The color red in RGB values">
Red
</SELECT>
<CANONICAL-URL "some-URL">
<IMG SRC="some-picture.gif" GRAYED-OUT>
<OPTION UNSELECTABLE>Some option
<A HREF="foo.html">
<IMG SRC="graphic.gif"
BORDER=0
MARK-IF-VISITED>
</A>
<A HREF="foo.html" NEVER-VISITED>
...
</A>
<INPUT TYPE="SUBMIT" NAME="Do it"
KEY="D">
<DEFINE NAME=1>
<IMG SRC="/image/gadget.gif" BORDER=0>
</DEFINE>
HTTP very much needs a way to solve this problem, either by requiring compliant clients to take notice of the above header fields, or by at least having a header field that would announce to the server what the user's cache preference setting is. Such a header field would at least allow a server to notify a user that a given service is likely to be unusable without a change of preferences.
The key contribution of this paper is to describe the constraints imposed on user interface design by this interaction medium, outline the tradeoffs in this design space, and motivate the choices we made in order to deliver our application over the web. We further outlined the lessons we learned and the design changes we made as the interface evolved in response to user feedback.
These issues are crucial because the growing popularity of the web ensures that this form of software delivery will become ever more wide-spread.
This application is available on the web at:
http://www-ksl-svc.stanford.edu:5915/
Model-based Virtual Document Generation. Technical Report KSL-95-80 (this is a hypertext paper best viewed here), Stanford University, Knowledge Systems Laboratory. 1995
![[Up]](up-button.gif)
![[Next]](Next_Button.gif)
These documents are indexed so that references to formal terms point to their definitions. They serve as introductions and reference manuals for the ontologies.
Below are the ontologies listed in alphabetical order, with the date of last modification.
3d-Tensor-Quantities 1 July 1994 Abstract-Algebra 2 May 1994 Basic-Matrix-Algebra 5 July 1994 Bibliographic-Data 27 September 1994 Cml 22 September 1994 Component-Assemblies 7 September 1994 Components-With-Constraints 30 July 1994 Dme-Cml 16 September 1994 Frame-Ontology 31 July 1994 Jat-Generic 29 April 1994 Job-Assignment-Task 29 June 1993 Kif-Extensions 5 October 1994 Kif-Lists 6 June 1994 Kif-Meta 10 July 1994 Kif-Numbers 8 April 1994 Kif-Relations 8 April 1994 Kif-Sets 8 September 1994 Mace-Domain 10 July 1994 Mechanical-Components 10 July 1994 Parametric-Constraints 31 July 1994 Physical-Quantities 31 July 1994 Quantity-Spaces 31 July 1994 Scalar-Quantities 1 July 1994 Simple-Geometry 5 July 1994 Slot-Constraint-Sugar 5 July 1994 Standard-Dimensions 21 September 1994 Standard-Units 21 September 1994 Tensor-Quantities 21 September 1994 Thermal-System 2 August 1994 Unary-Scalar-Functions 5 July 1994 User-Theory No source file available Vt-Design 30 July 1994 Vt-Domain 27 September 1994 Vt-Example 3 November 1993
Below is the lattice of ontologies in this library. Each ontology defines a set of formal terms. Ontologies include (import from) other ontologies. Terms in an included ontology are in the namespace of the ontologies that include it. In the lattice below, an ontology includes those ontologies that it is indented under.
Kif-Sets
Kif-Extensions
Frame-Ontology
Jat-Generic
Job-Assignment-Task
Basic-Matrix-Algebra
Tensor-Quantities
3d-Tensor-Quantities
Simple-Geometry
Mechanical-Components
Mace-Domain
Abstract-Algebra
Physical-Quantities
Standard-Dimensions
Vt-Design
Vt-Domain
Vt-Example
Unary-Scalar-Functions
Mace-Domain
Cml
Thermal-System
Dme-Cml
Thermal-System
Standard-Units
Simple-Geometry ...
Scalar-Quantities
Vt-Design ...
Unary-Scalar-Functions ...
Tensor-Quantities ...
Quantity-Spaces
Simple-Geometry ...
Parametric-Constraints
Components-With-Constraints
Vt-Design ...
Mace-Domain
Component-Assemblies
Mechanical-Components ...
Components-With-Constraints ...
Dme-Cml ...
Bibliographic-Data
Slot-Constraint-Sugar
Bibliographic-Data
Kif-Meta
Parametric-Constraints ...
Kif-Relations
Frame-Ontology ...
Kif-Extensions ...
Kif-Numbers
Kif-Extensions ...
Kif-Lists
Kif-Extensions ...
Kif-Meta ...
Kif-Relations ...
User-Theory
DME user interface showing the model of the Space Shuttle's Reaction Control
System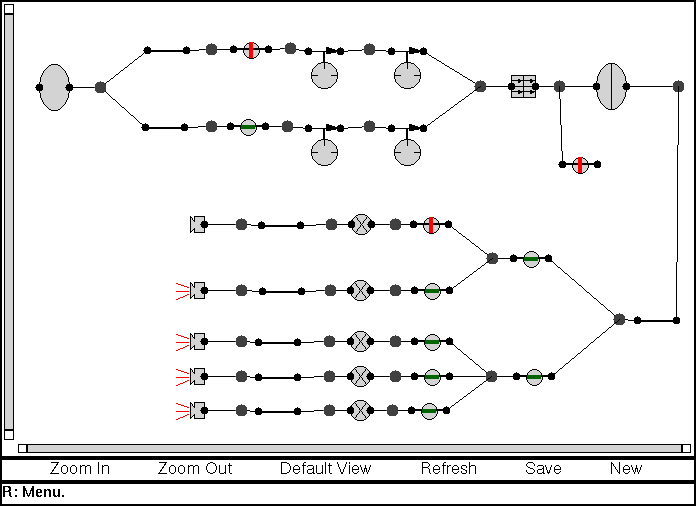
 Widgets using different browsers
Widgets using different browsersThe HTML code that generated these images can be found here.




 in front of the value Document of the Subclass-Of slot. This slot
says that Thesis is a subclass of Document, i.e. that Document is the Superclass
of Thesis. The other values of this slot shown in italics are inherited values.
in front of the value Document of the Subclass-Of slot. This slot
says that Thesis is a subclass of Document, i.e. that Document is the Superclass
of Thesis. The other values of this slot shown in italics are inherited values.
![[Back]](Back_Button.gif)




 Documentation:
An
official report on a bout of graduate work for which one receives a degree,
published by the university. Never mind that some fields make a big deal about
the difference between dissertations and theses. From the bibliographic
perspective, they are both of the same family.
Subclass-Of:
Document
Exhaustive-Subclass-Partition:
{
Masters-thesis,
Doctoral-thesis}
<New
Slot>: New
Value
New
Value
Doc.Author:
Slot-Cardinality:
1
Doc.Publication-Date:
Slot-Cardinality:
1
Doc.Title:
Slot-Cardinality:
1
Thesis.University:
Slot-Cardinality:
1
Slot-Value-Type:
University
What
about theses published as technical reports?
What
about theses published as technical reports?
Documentation:
An
official report on a bout of graduate work for which one receives a degree,
published by the university. Never mind that some fields make a big deal about
the difference between dissertations and theses. From the bibliographic
perspective, they are both of the same family.
Subclass-Of:
Document
Exhaustive-Subclass-Partition:
{
Masters-thesis,
Doctoral-thesis}
<New
Slot>: New
Value
New
Value
Doc.Author:
Slot-Cardinality:
1
Doc.Publication-Date:
Slot-Cardinality:
1
Doc.Title:
Slot-Cardinality:
1
Thesis.University:
Slot-Cardinality:
1
Slot-Value-Type:
University
What
about theses published as technical reports?
What
about theses published as technical reports?
We start our ontology editing session by going to the library so that we can load the ontology that we're going to edit. We will make an edit to an ontology called Documents-2 and will then show some of the other features provided by the ontology editor. The Documents-2 ontology contains definitions of terms that might be useful in describing documents. This ontology might be useful, for example, in the definition of the database schema for a bibliographic database.

If you are a new user, check out the guided tour.
Help is available on all pages by means of the "?" (help) button.



 is the Edit icon. Selecting it will allow you to edit the entry next to
the icon.
is the Edit icon. Selecting it will allow you to edit the entry next to
the icon.

 is the Add item icon. It allows you to add in an object that is already
known to the system. For example you would use the
is the Add item icon. It allows you to add in an object that is already
known to the system. For example you would use the  button to
add a slot to a class. Creation of new slots must be done by pushing on the
appropriate Create button.
button to
add a slot to a class. Creation of new slots must be done by pushing on the
appropriate Create button.

 indicates
in the class browser that a class is "open" and then all of its direct
subclasses (and instances if selected by user preference) are visible.
indicates
in the class browser that a class is "open" and then all of its direct
subclasses (and instances if selected by user preference) are visible.

 indicates in the class browser that a class is "closed" and that display of
the class's subclasses (and instances if selected by user preference) has been
suppressed.
indicates in the class browser that a class is "closed" and that display of
the class's subclasses (and instances if selected by user preference) has been
suppressed.
 is a button that will take you to the place that defined the value or object
following the icon.
is a button that will take you to the place that defined the value or object
following the icon.
The bibliographic-data ontology defines the terms used for describing bibliographic references. This theory defines the basic class for reference objects and the types (classes) for the data objects that appear in references, such as authors and titles. Specific databases will use schemata that associate references with various combinations of data objects, usually as fields in a record. This ontology is intended to provide the basic types from which a specific database schema might be defined.
Frame-Ontology Slot-Constraint-Sugar
No theories include Bibliographic-Data.
Biblio-Text
Biblio-Name
Title
Keyword
City-Address
Agent-Name
Author-Name
Publisher-Name
Biblio-Nl-Text
Biblio-Thing
Agent
Person
Author
Organization
Publisher
University
Conference
Timepoint
Calendar-Year
Calendar-Date
Universal-Time-Spec
Document
Book
Edited-Book
Periodical-Publication
Journal
Magazine
Newspaper
Proceedings
Thesis
Masters-Thesis
Doctoral-Thesis
Technical-Report
Miscellaneous-Publication
Technical-Manual
Computer-Program
Artwork
Cartographic-Map
Multimedia-Document
Reference
Publication-Reference
Book-Reference
Edited-Book-Reference
Book-Section-Reference
Article-Reference
Journal-Article-Reference
Magazine-Article-Reference
Newspaper-Article-Reference
Proceedings-Paper-Reference
Thesis-Reference
Doctoral-Thesis-Reference
Masters-Thesis-Reference
Technical-Report-Reference
Misc-Publication-Reference
Technical-Manual-Reference
Computer-Program-Reference
Cartographic-Map-Reference
Artwork-Reference
Multimedia-Document-Reference
Inherits-Author-From-Document
Book-Reference ...
Thesis-Reference ...
Technical-Report-Reference
Technical-Manual-Reference
Computer-Program-Reference
Cartographic-Map-Reference
Artwork-Reference
Multimedia-Document-Reference
Inherits-Publisher-From-Document
Book-Publication-Data-Constraint
Book-Reference ...
Book-Section-Reference
Inherits-Year-From-Document
Proceedings-Paper-Reference
Thesis-Reference ...
Technical-Report-Reference
Technical-Manual-Reference
Cartographic-Map-Reference
Artwork-Reference
Multimedia-Document-Reference
Book-Publication-Data-Constraint ...
Inherits-Title-From-Document
Book-Reference ...
Thesis-Reference ...
Technical-Report-Reference
Technical-Manual-Reference
Computer-Program-Reference
Cartographic-Map-Reference
Artwork-Reference
Multimedia-Document-Reference
Book-Publication-Data-Constraint ...
Non-Publication-Reference
Personal-Communication-Reference
Generic-Unpublished-Reference
Day-Number
Month-Name
Year-Number
Author.Name Doc.Author Doc.Author-Name Doc.Editor Doc.Series-Editor Doc.Translator Penname Publisher.Address Ref.Address Ref.Author Ref.Editor Ref.Keywords Ref.Labels Ref.Notes Ref.Secondary-Author Ref.Secondary-Title Ref.Series-Editor Ref.Tertiary-Author Ref.Translator
Agent.Name Conf.Address Conf.Date Conf.Name Conf.Organization Doc.Author.Name Doc.Conference Doc.Edition Doc.Institution Doc.Number-Of-Pages Doc.Publication-Date Doc.Publisher Doc.Series-Title Doc.Title Organization.Name Publisher.Name Ref.Abstract Ref.Booktitle Ref.Day Ref.Document Ref.Edition Ref.Issue Ref.Magazine-Name Ref.Month Ref.Newspaper-Name Ref.Number-Of-Volumes Ref.Organization Ref.Pages Ref.Periodical Ref.Publisher Ref.Report-Number Ref.Title Ref.Type-Of-Work Ref.Volume Ref.Year Thesis.University Timepoint.Day Timepoint.Minutes Timepoint.Month Timepoint.Seconds Timepoint.Year
April August December February January July June March May November October September
The following constants were used from included theories:
All constants that were mentioned were defined.
#<Class-Definition Article-Reference 272411E>,
#<Class-Definition Artwork-Reference 2723DFE>,
#<Class-Definition Author-Name 27240BE>,
#<Function-Definition Author.Name-Of 2723DEE>,
#<Class-Definition Biblio-Name 2723EFE>,
#<Class-Definition Biblio-Nl-Text 272414E>,
#<Class-Definition Biblio-Text 2723FFE>,
#<Class-Definition Book-Publication-Data-Constraint 272412E>,
#<Class-Definition Book-Reference 2723E4E>,
#<Class-Definition Book-Section-Reference 272419E>,
#<Class-Definition Cartographic-Map-Reference 272403E>,
#<Class-Definition City-Address 272415E>,
#<Class-Definition Computer-Program-Reference 2723F6E>,
#<Function-Definition Conf.Address 272409E>,
#<Function-Definition Conf.Date 272417E>,
#<Function-Definition Conf.Organization 2723F0E>,
#<Class-Definition Conference 2723E5E>,
#<Function-Definition Conference-Of augmented in Bibliographic-Data 272422E>,
#<Class-Definition Doctoral-Thesis-Reference 27240FE>,
#<Class-Definition Edited-Book-Reference 27241FE>,
#<Function-Definition Edition-Of 2723E7E>,
#<Class-Definition Generic-Unpublished-Reference 27241EE>,
#<Relation-Definition Has-Author-Name 2723F5E>,
#<Relation-Definition Has-Name augmented in Bibliographic-Data 27240DE>,
#<Relation-Definition Has-Penname 27241CE>,
#<Relation-Definition Has-Textual-Representation 272404E>,
#<Class-Definition Inherits-Author-From-Document 2723F7E>,
#<Class-Definition Inherits-Publisher-From-Document 272428E>,
#<Class-Definition Inherits-Title-From-Document 272429E>,
#<Class-Definition Inherits-Year-From-Document 27240CE>,
#<Class-Definition Journal-Article-Reference 272425E>,
#<Class-Definition Keyword 2723E0E>,
#<Class-Definition Magazine-Article-Reference 272418E>,
#<Class-Definition Masters-Thesis-Reference 2723ECE>,
#<Class-Definition Misc-Publication-Reference 272413E>,
#<Class-Definition Multimedia-Document-Reference 27241DE>,
#<Function-Definition Name augmented in Bibliographic-Data 272401E>,
#<Class-Definition Newspaper-Article-Reference 2723DDE>,
#<Class-Definition Non-Publication-Reference 272402E>,
#<Class-Definition Personal-Communication-Reference 272424E>,
#<Class-Definition Proceedings augmented in Bibliographic-Data 2723FAE>,
#<Class-Definition Proceedings-Paper-Reference 272423E>,
#<Class-Definition Publication-Reference 2723E2E>,
#<Class-Definition Publisher-Name 2723EBE>,
#<Relation-Definition Publisher.Address 272426E>,
#<Function-Definition Ref.Abstract 2723E6E>,
#<Relation-Definition Ref.Address 2723F4E>,
#<Relation-Definition Ref.Author 27240AE>,
#<Function-Definition Ref.Booktitle 272420E>,
#<Function-Definition Ref.Day 2723F3E>,
#<Function-Definition Ref.Document 27241BE>,
#<Function-Definition Ref.Edition 2723FBE>,
#<Relation-Definition Ref.Editor 2723DCE>,
#<Function-Definition Ref.Issue 2723F8E>,
#<Relation-Definition Ref.Keywords 2723EAE>,
#<Relation-Definition Ref.Labels 2723E9E>,
#<Function-Definition Ref.Magazine-Name 2723FDE>,
#<Function-Definition Ref.Month 272408E>,
#<Function-Definition Ref.Newspaper-Name 272410E>,
#<Relation-Definition Ref.Notes 2723E8E>,
#<Function-Definition Ref.Number-Of-Volumes 27240EE>,
#<Function-Definition Ref.Organization 272407E>,
#<Function-Definition Ref.Pages 272406E>,
#<Function-Definition Ref.Periodical 272421E>,
#<Function-Definition Ref.Publisher 272400E>,
#<Function-Definition Ref.Report-Number 2723F1E>,
#<Relation-Definition Ref.Secondary-Author 27241AE>,
#<Relation-Definition Ref.Secondary-Title 272405E>,
#<Relation-Definition Ref.Series-Editor 2723E1E>,
#<Relation-Definition Ref.Tertiary-Author 272427E>,
#<Relation-Definition Ref.Translator 2723DBE>,
#<Function-Definition Ref.Type-Of-Work 272416E>,
#<Function-Definition Ref.Volume 2723E3E>,
#<Function-Definition Ref.Year 2723EEE>,
#<Class-Definition Reference 2723F2E>,
#<Class-Definition Technical-Manual-Reference 2723F9E>,
#<Class-Definition Technical-Report-Reference 2723FCE>,
#<Class-Definition Thesis-Reference 2723FEE>,
#<Class-Definition Title augmented in Bibliographic-Data 2723EDE>
 button that enables editing commands.
button that enables editing commands.
All of the non-functioning links in the mockups should now be marked as
visited. Go here
to get back up to the top-level of the mockups.
[Add Slot on Instances] [Add Slot on Class] [Add Axiom] [Add Note] [Create Instance] [Rename Class] [Delete Class] [Help]
[Add Slot on Instances] [Add Slot on Class] [Add Axiom] [Add Note] [Create Instance] [Rename Class] [Delete Class] [Help]
[Add Slot on Instances] [Add Slot on Class] [Add Axiom] [Add Note] [Create Instance] [Rename Class] [Delete Class] [Help]

 Documentation:
An
official report on a bout of graduate work for which one receives a degree,
published by the university. Never mind that some fields make a big deal about
the difference between dissertations and theses. From the bibliographic
perspective, they are both of the same family.
Subclass-Of:
Document
Exhaustive-Subclass-Partition:
{
Masters-thesis,
Doctoral-thesis}Doc.Author:
_
Slot-Cardinality:
1
Doc.Publication-Date:
Slot-Cardinality:
1
Doc.Title:
Slot-Cardinality:
1
Thesis.University:
Slot-Cardinality:
1
Slot-Value-Type:
University
What
about theses published as technical reports?
What
about theses published as technical reports?
Documentation:
An
official report on a bout of graduate work for which one receives a degree,
published by the university. Never mind that some fields make a big deal about
the difference between dissertations and theses. From the bibliographic
perspective, they are both of the same family.
Subclass-Of:
Document
Exhaustive-Subclass-Partition:
{
Masters-thesis,
Doctoral-thesis}Doc.Author:
_
Slot-Cardinality:
1
Doc.Publication-Date:
Slot-Cardinality:
1
Doc.Title:
Slot-Cardinality:
1
Thesis.University:
Slot-Cardinality:
1
Slot-Value-Type:
University
What
about theses published as technical reports?
What
about theses published as technical reports?
[Add Slot on Instances] [Add Slot on Class] [Add Axiom] [Add Note] [Create Instance] [Rename Class] [Delete Class] [Help]
An official report on a bout of graduate work for which one receives a degree, published by the university. Never mind that some fields make a big deal about the difference between dissertations and theses. From the bibliographic perspective, they are both of the same family.
If it is cited as a TR, it is a TR.
One can imagine adding a cross-reference field to references that points to associated documents or other references.
An object of class: ONTOLINGUA-INTERNAL::ONTOLOGY
From class: GFP:KB
FORMAT: :NEW
PACKAGE: #<Package "ONTOLINGUA-USER" 19086AE>
GFP::DBD: Unbound
GFP::DBMS-HOST: Unbound
GFP::DBMS-TYPE: :FILE
GFP::DEPENDENCIES: Unbound
GFP::EXTRA: Unbound
GFP::FILENAME: NIL
GFP::ID: Unbound
GFP::IN-MEMORY-P: NIL
GFP::NAME: ONTOLINGUA-USER::BIBLIOGRAPHIC-DATA
GFP::PARENTS: Unbound
GFP::RECORD-MODIFICATIONS?: Unbound
GFP::STATE: :LIVE
GFP::TESTFN: #<Compiled-Function EQ 12B0866>
From class: ONTOLINGUA-INTERNAL::DEFINITIONS-MIXIN
ONTOLINGUA-INTERNAL::DEFINITIONS: #<Hash-Table 272391E>
ONTOLINGUA-INTERNAL::REFERENCED-ONTOLOGIES: (#<ONTOLOGY KIF-LISTS 194F42E> #<ONTOLOGY KIF-EXTENSIONS 195F0F6> #<ONTOLOGY AGENTS 1BA6466>...)
From class: ONTOLINGUA-INTERNAL::GETHASH-FAST-INDEX-MIXIN
UTILITIES::TRIE-HASH-KEY: #:||
From class: ONTOLINGUA-INTERNAL::ONTOLINGUA-REASONING-MIXIN
ONTOLINGUA-INTERNAL::EK-THEORY-NAME: ONTOLINGUA-INTERNAL::INTERNAL-EK-THEORY-BIBLIOGRAPHIC-DATA-65
ONTOLINGUA-INTERNAL::ONTOLINGUA-INTERNAL-RE-KB: #<ONTOLINGUA-RE-KB BIBLIOGRAPHIC-DATA 1BBC986>
ONTOLINGUA-INTERNAL::REFERENCE-COUNTS: #<Structure UTILITIES::STRING=-TRIE 1BBC2CE>
From class: ONTOLINGUA-INTERNAL::ONTOLOGY
ONTOLINGUA-INTERNAL::BUILT-IN-P: T
ONTOLINGUA-INTERNAL::CLASSES-IMPLICITLY-DEFINING-SLOTS: NIL
ONTOLINGUA-INTERNAL::DIRTY-P: NIL
ONTOLINGUA-INTERNAL::GENERALITY: :VERY-LOW
ONTOLINGUA-INTERNAL::IMPLICIT-SLOTS-CHECKED?: T
ONTOLINGUA-INTERNAL::INCLUDED-ONTOLOGIES: (#<ONTOLOGY SIMPLE-TIME 1B9A116> #<ONTOLOGY AGENTS 1BA6466> #<ONTOLOGY FRAME-ONTOLOGY 1926266>...)
ONTOLINGUA-INTERNAL::INITIALIZED-IN-MEMORY-P: NIL
ONTOLINGUA-INTERNAL::IO-PACKAGE: #<Package "ONTOLINGUA-USER" 19086AE>
ONTOLINGUA-INTERNAL::IO-READTABLE: #<Readtable 1D3A74E>
ONTOLINGUA-INTERNAL::MATURITY: :HIGH
ONTOLINGUA-INTERNAL::NAME: ONTOLINGUA-USER::BIBLIOGRAPHIC-DATA
ONTOLINGUA-INTERNAL::NOTES: ("Author: Thomas Gruber..." "The objective of this ontology is to define the concepts and
..." "ACKNOWLEDGEMENTS: Many thanks to Richard Fikes, who helped with the..."...)
ONTOLINGUA-INTERNAL::ONTOLOGY-DOCUMENTATION: "The bibliographic-data ontology defines the terms used for describing..."
ONTOLINGUA-INTERNAL::ONTOLOGY-INDEX: (#<Word Article-Reference in Bibliographic-Data> #<Word Artwork-Reference in Bibliographic-Data> #<Word Author-Name in Bibliographic-Data>...)
ONTOLINGUA-INTERNAL::ONTOLOGY-USE-LIST: (#<ONTOLOGY SIMPLE-TIME 1B9A116> #<ONTOLOGY AGENTS 1BA6466> #<ONTOLOGY FRAME-ONTOLOGY 1926266>...)
ONTOLINGUA-INTERNAL::PLIST: (ONTOLINGUA-INTERNAL::RULE-ENGINE-KB #<ONTOLINGUA-RE-KB BIBLIOGRAPHIC-DATA 5EE0DAE>)
ONTOLINGUA-INTERNAL::READ-ONLY-P: T
ONTOLINGUA-INTERNAL::SLOTS-IMPLICITLY-DEFINED-IN-ONTOLOGY: NIL
ONTOLINGUA-INTERNAL::SOURCE-FORMS: #<Hash-Table 2739AC6>
ONTOLINGUA-INTERNAL::STATIC-P: T
ONTOLINGUA-INTERNAL::STUB-P: NIL
From class: ONTOLINGUA-INTERNAL::SOURCE-FILE-MIXIN
ONTOLINGUA-INTERNAL::SOURCE-FILE: #P"/tmp_mnt/vol/q/htw/ontolingua/examples/biblio/bibliographic-data.lisp"
ONTOLINGUA-INTERNAL::SOURCE-FILE-WRITE-DATE: 3024100016
From class: ONTOLINGUA-INTERNAL::SYMBOL-TABLE-MIXIN
ONTOLINGUA-INTERNAL::BACK-TRANSLATIONS: #<Hash-Table 2739806>
ONTOLINGUA-INTERNAL::PRIVATE-BY-DEFAULT: NIL
ONTOLINGUA-INTERNAL::PRIVATE-WORDS: #<Hash-Table 27390B6>
ONTOLINGUA-INTERNAL::SHADOWED-WORDS: #<Hash-Table 2738E46>
ONTOLINGUA-INTERNAL::SYMBOL-TABLE: #<Hash-Table 27389A6>
ONTOLINGUA-INTERNAL::TRANSLATIONS: #<Hash-Table 2739596>
ONTOLINGUA-INTERNAL::USER-SPECIFIED-PUBLIC-WORDS: #<Hash-Table 2739326>
From class: ONTOLINGUA-INTERNAL::TRANSLATION-ARGS-MIXIN
ONTOLINGUA-INTERNAL::TRANSLATION-ARGS: (#<ONTOLOGY BIBLIOGRAPHIC-DATA 1BBC1F6>)
Classes:
Article-Reference,
Artwork-Reference,
Author-Name,
Biblio-Name,
Biblio-Nl-Text,
Biblio-Text,
Book-Publication-Data-Constraint,
Book-Reference,
Book-Section-Reference,
Cartographic-Map-Reference,
City-Address,
Computer-Program-Reference,
Conference,
Doctoral-Thesis-Reference,
Edited-Book-Reference,
Generic-Unpublished-Reference,
Inherits-Author-From-Document,
Inherits-Publisher-From-Document,
Inherits-Title-From-Document,
Inherits-Year-From-Document,
Journal-Article-Reference,
Keyword,
Magazine-Article-Reference,
Masters-Thesis-Reference,
Misc-Publication-Reference,
Multimedia-Document-Reference,
Newspaper-Article-Reference,
Non-Publication-Reference,
Personal-Communication-Reference,
Proceedings,
Proceedings-Paper-Reference,
Publication-Reference,
Publisher-Name,
Reference,
Technical-Manual-Reference,
Technical-Report-Reference,
Thesis-Reference,
TitleInstances:
Author.Name-Of,
Conf.Address,
Conf.Date,
Conf.Organization,
Conference-Of,
Edition-Of,
Has-Author-Name,
Has-Name,
Has-Penname,
Has-Textual-Representation,
Name,
Publisher.Address,
Ref.Abstract,
Ref.Address,
Ref.Author,
Ref.Booktitle,
Ref.Day,
Ref.Document,
Ref.Edition,
Ref.Editor,
Ref.Issue,
Ref.Keywords,
Ref.Labels,
Ref.Magazine-Name,
Ref.Month,
Ref.Newspaper-Name,
Ref.Notes,
Ref.Number-Of-Volumes,
Ref.Organization,
Ref.Pages,
Ref.Periodical,
Ref.Publisher,
Ref.Report-Number,
Ref.Secondary-Author,
Ref.Secondary-Title,
Ref.Series-Editor,
Ref.Tertiary-Author,
Ref.Translator,
Ref.Type-Of-Work,
Ref.Volume,
Ref.Year
Value: UnBound Function: UnBound PName: "BIBLIOGRAPHIC-DATA" Package: #<Package "ONTOLINGUA-USER" 19086AE> Plist: NIL Documentation: none
(In-Package "ONTOLINGUA-USER")
;;; Written by user Rse from session "hacking2" owned by group JUST-ME
;;; Date: Oct 27, 1995 1520
(Define-Ontology
Bibliographic-Data
(Simple-Time Agents Frame-Ontology Slot-Constraint-Sugar documents)
"The bibliographic-data ontology defines the terms used for describing
bibliographic references. This ontology defines the basic class for
reference objects and the types (classes) for the data objects that
appear in references, such as authors and titles. Specific databases
will use schemata that associate references with various combinations
of data objects, usually as fields in a record. This ontology is
intended to provide the basic types from which a specific database
schema might be defined."
:Generality
:very-low
:maturity :high
:Io-Package
"ONTOLINGUA-USER"
:Issues
("Author: Thomas Gruber
Version: 3"
"The objective of this ontology is to define the concepts and
relationships that underlie a family of databases and tools in the
domain of bibliographies. Such a conceptualization is intended to
help with automatic translation among existing databases, to enable
the development of reference-formatting styles that are independent of
database or tool, and to support remote services such as bibliography
database search and reference-list generation.
An ontology can be partitioned into ontologies. This file contains the
BIBLIOGRAPHIC-DATA ontology, which establishes the basic terminology.
Child ontologies that include (specialize) the bibliographic-data ontology
will describe the constraints of specific bibliographic databases and tools.
Basic ontological commitments:
A bibliography is made up of references. A REFERENCE describes the
information needed to identify and retrieve a publication. A publication is
associated with a DOCUMENT of some sort (e.g., a book or journal). In some
cases there are several publications per document (e.g., papers in an edited
collection). Thus documents are distinguished from references. Documents
are created by AUTHOR s, which are PEOPLE or other agents (e.g.,
ORGANIZATION ). They are published by PUBLISHER s or other organizations.
Bibliographic-Data includes a simple ontology of time, Time-Points. A TIMEPOINT is a specification
of a single point in historical time. CALENDAR-DATE is a timepoint at the
resolution of days; that is, the day, month, and year are known. A
CALENDAR-YEAR is a timepoint at the resolution of years. The publication
date of a DOCUMENT is some kind of timepoint; for many publications only
the year is known. Events such as a CONFERENCE also occur on dates specified
with timepoints.
All documents have titles. TITLEs are names (strings of characters), as are
AGENT-NAME s, CITY-ADDRESS es, and other data types that are used as
identifiers and are not further destructured. The class called BIBLIO-NAME
is a place holder for these atomic identifiers. The class BIBLIO-NL-TEXT is
for strings of characters meant for human reading, rather than as an
identifier.
The most interesting ontological commitment is the distinction between the
data fields in a reference and the facts about documents. Facts are stated
as relationships over and properties of explicitly-represented objects. For
example, some facts are about publishers: the publisher name, the city with
which the publisher is associated, and the year of (latest) publication. In
a document, the PUBLISHER-OF is an ORGANIZATION. In a REFERENCE, the
REF.PUBLISHER is the NAME of the publisher, and the REF.ADDRESS is
the PUBLISHER.ADDRESS of the document's publisher. The REF.YEAR of the
reference is a number, which is the year-of of the
Publication-Date-Of (a timepoint) of the document associated with a
reference. Thus, in a reference -- the entity we are trying to share -- many
of the facts have been mapped onto these atomic data types such as name
strings, title strings, and numbers. In a document, some of the meaning of
these data types can be stated as logical constraints. This is in the spirit
of the Cyc project, which aims to provide the background knowledge behind the
narrow, brittle representations of expert systems and conventional databases.
This distinction between data in references and facts in other parts of the
ontology is there to support the interoperability of tools that commit to
this ontology, and the integration of this ontology and associated databases
with other ontologies and databases. Part of the incompatibility between
bibliography databases and tools is due to different _encodings_ and
_presentations_ of the same information. For example, one database might
encode a date as a string, another as a structured record of integer fields.
Their ontological commitments might be the same -- they might both support
years and months for a magazine article reference -- but their encodings mask
their conceptual agreement. Similarly, different bibliography formatting
styles might disagree on whether a publisher city is required for a given
reference type, but they both agree that the city is a function of the
publisher (not a name for it found in some reference field). Explicitly
representing agents (authors), organizations (publishers), events
(conferences), and time (publication dates) as objects in the
conceptualization allows one to write knowledge-full constraints about how
the data fields are related. Capturing these constraints is part of good
database design, because it reduces redundancy and anticipates integration
with other databases. For example, associating author and publisher _names_
(which are all that appear in references) with independently defined agents
ensures that these agents will be named consistently in the references and
facilitates the importation of data on authors and publishers from other
databases.
This ontology is a set of definitions of classes, relations, and functions.
It is represented in Ontolingua forms, which use KIF as the formal language
and English documentation strings to describe meanings that we haven't
formalized. We are using a slightly new-and-improved syntax for Ontolingua,
in which the result variable of a function resides next to the argument list.
Also, some new second-order relations are introduced (SAME-VALUES,
HAS-SOME, HAS-ONE, CAN-HAVE-ONE, CANNOT-HAVE, HAS-ONE-OF-TYPE, COMPOSE).
These are defined in an ontology called slot-constraint-sugar, and ontolingua
turns sentences in these forms into their canonical forms using the
frame ontology vocabulary (value-cardinality, value-type, etc.)."
"ACKNOWLEDGEMENTS: Many thanks to Richard Fikes, who helped with the
formalization and style decisions, and Fritz Mueller, who implemented
Ontolingua code to support these definitions. This work is supported
by DARPA."
"We used to say that
(Subclass-Partition Biblio-Thing
(Setof Agent Timepoint Document Reference Conference))
but now we've ditched biblio-thing. We could make this a stand-alone axiom
or an augmentation of individual-thing."
"Substantially hacked by JPR and AXF to remove any reasonably general stuff
on 30-Oct-95."
(:Copyright "Copyright (c) 1992 Thomas R. Gruber"))
:Intern-In
((Kif-Extensions String) (Kif-Lists Rest First List)
(Kif-Numbers Integer Natural)))
(In-Ontology (Quote Bibliographic-Data))
;;; ------------------ Classes --------------
;;; Article-Reference
(Define-Class Article-Reference
(?Ref)
"An article is a piece published in a journal, magazine, or newspaper."
:Def
(And (Publication-Reference ?Ref)
(Value-Type ?Ref Ref.Document Periodical-Publication)
(Has-Some ?Ref Ref.Author) (Has-One ?Ref Title-Of)
(Has-One ?Ref Ref.Year) (Has-One ?Ref Ref.Periodical)
(Same-Values ?Ref Ref.Periodical
(Compose Title-Of Ref.Document))
(Same-Values ?Ref Ref.Secondary-Title Ref.Periodical)))
;;; Artwork-Reference
(Define-Class Artwork-Reference
(?Ref)
"A reference to a work of art that does not fit the other categories of
documents. The author is the artist."
:Def
(And (Misc-Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)))
;;; Author-Name
(Define-Class Author-Name
(?Name)
"A string that is used as the name of some author.
Often databases of author names are kept separately from
databases of people or documents."
:Constraints
(Biblio-Name ?Name)
:Issues
("see the discussion of AGENT-NAME."))
;;; Biblio-Name
(Define-Class Biblio-Name
(?name)
"A name of something in the bibliographic-data ontology.
Names are distinguished from strings in general because
they may be treated specially in some databases; for example,
there may be uniqueness assumptions."
:Def
(Biblio-Text ?name)
:axiom-def
(subclass-partition biblio-name
Title Keyword City-Address)
:Issues
(("Why isn't there a subclass-partition for this, since
classes like TITLE, KEYWORD, and CITY-ADDRESS are
subclasses?"
"Because these are all _strings_ that may be lexically
equal. If they were _concepts_ then they would be
mutually exclusive."
"Fixed by AXF and JPR when we changed biblio-text to have
a textual representation slot.")))
;;; Biblio-Nl-Text
(Define-Class Biblio-Nl-Text
(?text)
"A string of natural language text mentioned in some bibliographic
reference. Texts are distinguished from strings in general because
they may be treated specially in some databases, or presented as
free-flowing text to a human reader. BIBLIO-NL-TEXT's are used for
different purposes than biblio-names. BIBLIO-NL-TEXT's are for things like
notes and abstracts; BIBLIO-NAME's are meant to identify some object or
some property."
:Def
(Biblio-Text ?text)
:Issues
((:See-Also Biblio-Name)))
;;; Biblio-Text
(define-relation has-textual-representation (?x ?string)
"The textual representation of a text object. This is a relation rather
than a function because the textual representation of a thing could
have manifestations in multiple languages or formats."
:def (and (individual-thing ?x) (string ?string)))
(Define-Class Biblio-Text
(?x)
"The most general class of undifferentiated text objects."
:Def
(and (Individual-thing ?x)
(has-some ?x has-textual-representation))
:Issues
(("Why not make biblio-name and biblio-nl-text be disjoint
subclasses of biblio-text?"
"There may be valid names that are exactly the same strings
as NL texts, so it would be overconstraining to require
these two classes to be disjoint. The distinction between
names and NL texts is in their intended use, rather than
their forms. This happens because we don't represent what
the strings denote. If we did, then we could offer a
formal basis for distinguishing between these two classes
of text strings.")))
;;; Biblio-Thing
;(Define-Class Biblio-Thing
; (?X)
; "Biblio-thing is the root of the bibliographic ontology.
;It is the superclass-of anything that would otherwise be a
;a completely standalone primitive (i.e., a root of the class
;hierarchy)."
; :Def
; (Individual-Thing ?X)
; :Axiom-Def
; (Subclass-Partition Biblio-Thing
; (Setof Agent Timepoint Document Reference Conference))
; :Issues
; ("Removed biblio-text because it is a subclass-of STRING."
; "Added CONFERENCE because it is a subclass-of biblio-thing
; and it is disjoint from these other primitive classes."))
;;; Book
;;; Book-Publication-Data-Constraint
(Define-Relation Book-Publication-Data-Constraint
(?Ref)
"In references associated with books, the reference fields
for publication data such as publisher, place, and edition
are all taken from the data on the book-document itself.
This unary relation captures these constraints in one place,
so that each of the book reference types can just inherit them."
:Iff-Def
(And (Publication-Reference ?Ref)
(Has-One-Of-Type ?Ref Ref.Document Book)
(Has-One ?Ref Ref.Publisher)
(Inherits-Publisher-From-Document ?Ref)
(Has-One ?Ref Ref.Year) (Inherits-Year-From-Document ?Ref)))
;;; Book-Reference
(Define-Class Book-Reference
(?Ref)
"A book reference. Book references usually include complete publisher
information, and may have a series editor and title, edition, and translator.
A reference to a book gets many of its publication data from the book qua
document."
:Def
(And (Publication-Reference ?Ref)
(Has-One-Of-Type ?Ref Ref.Document Book)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Book-Publication-Data-Constraint ?Ref)
(Same-Values ?Ref Ref.Secondary-Author Ref.Series-Editor)
(Same-Values ?Ref Ref.Secondary-Title Series-Title-Of)))
;;; Book-Section-Reference
(Define-Class Book-Section-Reference
(?Ref)
"A section of a book, like a chapter or a paper in an edited collection."
:Def
(And (Publication-Reference ?Ref)
(Has-One-Of-Type ?Ref Ref.Document Edited-Book)
(Has-Some ?Ref Ref.Author) (Has-Some ?Ref Ref.Editor)
(Has-One ?Ref Ref.Booktitle)
(Same-Values ?Ref Ref.Booktitle
(Compose Title-Of Ref.Document))
(Book-Publication-Data-Constraint ?Ref)
(Same-Values ?Ref Ref.Secondary-Author Ref.Editor)
(Same-Values ?Ref Ref.Tertiary-Author Ref.Series-Editor)))
;;; Cartographic-Map
;;; Cartographic-Map-Reference
(Define-Class Cartographic-Map-Reference
(?Ref)
"A reference to a map created by a cartographer."
:Def
(And (Misc-Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)))
;;; City-Address
(Define-Class City-Address
(?Name)
"A city-address is a string that identifies a city
somewhere in the world. We distinguish it from other
names to facilitate integrating it with ontologies that
include representations for locations and alternative ways
of identifying places."
:Def
(Biblio-Name ?Name))
;;; Computer-Program
;;; Computer-Program-Reference
(Define-Class Computer-Program-Reference
(?Ref)
"A reference to a computer program. The title-of is the name of the
program. The author is the programmer."
:Def
(And (Misc-Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)))
;;; Conference
;;; Augmentation
(Define-Class Proceedings
(?X)
"The published proceedings of a conference, workshop, or similar
meeting. If the proceedings appear as an edited book, the document
is an edited book with a title other than ``proceedings of...''
Proceedings may have editors, however."
:Def
(And (Has-One-Of-Type ?X Conference-Of Conference)
(Same-Values ?X Title-Of (Compose Name Conference-Of)))
:Issues
("We are assuming that the title of the proceedings is
the same as the name of the conferences. This may be
bogus."))
(Define-Class Conference
(?X)
"A conference is a big meeting where people wear badges, sit through
boring talks, and drink coffee in the halls."
:Def
(And (Individual-Thing ?X)
(Has-One-Of-Type ?X Name Biblio-Name)
(Has-One-Of-Type ?X Conf.Organization Organization)
(Has-One-Of-Type ?X Conf.Date Calendar-Date)
(Value-Type ?X Conf.Address City-Address)
(Can-Have-One ?X Conf.Address)))
(Define-Function Conference-Of
(?proc)
:->
?Conference
"The conference associated with a proceedings."
:Def (And (Proceedings ?proc)))
;;; Doctoral-Thesis-Reference
(Define-Class Doctoral-Thesis-Reference
(?Ref)
:Def
(And (Thesis-Reference ?Ref)
(Value-Type ?Ref Ref.Document Doctoral-Thesis)
(Has-Value ?Ref Ref.Type-Of-Work "Doctoral Thesis")))
;;; Edited-Book-Reference
(Define-Class Edited-Book-Reference
(?Ref)
"like a book-reference, except the document is an edited-book and
the author and editor are the same."
:Iff-Def
(And (Book-Reference ?Ref)
(Has-One-Of-Type ?Ref Ref.Document Edited-Book)
(Has-Some ?Ref Ref.Editor)
(Same-Values ?Ref Ref.Author Ref.Editor)))
;;; Generic-Unpublished-Reference
(Define-Class Generic-Unpublished-Reference
(?Ref)
:Def
(Non-Publication-Reference ?Ref))
;;; Inherits-Author-From-Document
(Define-Relation Inherits-Author-From-Document
(?Ref)
"When a reference is a one-to-one account of a document, then the author
in the reference (ref.author) is the name of the author of the document.
This relation captures this relationship."
:Iff-Def
(And (Publication-Reference ?Ref)
(Same-Values ?Ref Ref.Author
(Compose Has-Author-Name Ref.Document))))
;;; Inherits-Publisher-From-Document
(Define-Relation Inherits-Publisher-From-Document
(?Ref)
"When a reference is a one-to-one account of a document, then the publisher
in the reference (ref.publisher) is the name of the publisher of the
document. This relation captures this relationship. Inherits the
publisher's address as well."
:Iff-Def
(And (Publication-Reference ?Ref)
(Same-Values ?Ref Ref.Publisher
(Compose Name Publisher-Of Ref.Document))
(Same-Values ?Ref Ref.Address
(Compose Publisher.Address Publisher-Of Ref.Document))))
;;; Inherits-Title-From-Document
(Define-Relation Inherits-Title-From-Document
(?Ref)
:Iff-Def
(And (Publication-Reference ?Ref)
(Same-Values ?Ref Title-Of
(Compose Title-Of Ref.Document))))
;;; Inherits-Year-From-Document
(Define-Relation Inherits-Year-From-Document
(?Ref)
"When a reference is a one-to-one account of a document, then the year
in the reference (ref.year) is the year of publication of the document.
This relation captures this relationship."
:Iff-Def
(And (Publication-Reference ?Ref)
(Same-Values ?Ref Ref.Year
(Compose year-of Publication-Date-Of
Ref.Document))))
;;; Journal-Article-Reference
(Define-Class Journal-Article-Reference
(?Ref)
"A reference to article in a journal must give information sufficient to
find the issue containing the article."
:Def
(And (Article-Reference ?Ref)
(Value-Type ?Ref Ref.Document Journal)
(Cannot-Have ?Ref Ref.Month)))
;;; Keyword
(Define-Class Keyword
(?Keyword)
"A keyword is a string used as an index."
:Def
(Biblio-Name ?Keyword))
;;; Magazine-Article-Reference
(Define-Class Magazine-Article-Reference
(?Ref)
"A reference to an article in a magazine is essentially the same as a
journal article reference. Some formatting styles need the distinction.
Magazine article references sometimes include the month instead of the
volume/issue numbers."
:Def
(And (Article-Reference ?Ref)
(Value-Type ?Ref Ref.Document Magazine)
(Has-One ?Ref Ref.Magazine-Name)
(Same-Values ?Ref Ref.Magazine-Name Ref.Periodical)))
;;; Masters-Thesis-Reference
(Define-Class Masters-Thesis-Reference
(?Ref)
:Def
(And (Thesis-Reference ?Ref)
(Value-Type ?Ref Ref.Document Masters-Thesis)
(Has-Value ?Ref Ref.Type-Of-Work "Masters Thesis")))
;;; Misc-Publication-Reference
(Define-Class Misc-Publication-Reference
(?Ref)
:Def
(Publication-Reference ?Ref)
:Axiom-Def
(Subclass-Partition Misc-Publication-Reference
(Setof Technical-Manual-Reference Computer-Program-Reference
Cartographic-Map-Reference Artwork-Reference
Multimedia-Document-Reference)))
;;; Multimedia-Document
;;; Multimedia-Document-Reference
(Define-Class Multimedia-Document-Reference
(?Ref)
"A bibliographic reference to a multimedia document.
Who knows what conventions the future holds for these things."
:Def
(And (Misc-Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)))
;;; Newspaper-Article-Reference
(Define-Class Newspaper-Article-Reference
(?Ref)
"A newspaper article reference is like a magazine article reference"
:Def
(And (Article-Reference ?Ref)
(Value-Type ?Ref Ref.Document Newspaper)
(Has-One ?Ref Ref.Newspaper-Name)
(Same-Values ?Ref Ref.Magazine-Name Ref.Periodical)
(Has-One ?Ref Ref.Month) (Has-One ?Ref Ref.Day)
(Value-Type ?Ref Ref.Address City-Address)))
;;; Non-Publication-Reference
(Define-Class Non-Publication-Reference
(?Ref)
"A reference to something that just isn't a document."
:Def
(And (Reference ?Ref) (Cannot-Have ?Ref Ref.Document))
:Axiom-Def
(Subclass-Partition Non-Publication-Reference
(Setof Personal-Communication-Reference
Generic-Unpublished-Reference)))
;;; Personal-Communication-Reference
(Define-Class Personal-Communication-Reference
(?Ref)
"A reference to a personal communication between the author of the paper in
which the bibliography appears and some other person. The ref.author of the
reference is the person with whom the conversation was held."
:Def
(And (Non-Publication-Reference ?Ref) (Has-One ?Ref Ref.Author)
(Has-One ?Ref Ref.Year) (Has-One ?Ref Ref.Month)
(Has-One ?Ref Ref.Day)))
;;; Proceedings-Paper-Reference
(Define-Class Proceedings-Paper-Reference
(?Ref)
"An article appearing in the published proceedings of some conference or
workshop."
:Def
(And (Publication-Reference ?Ref)
(Value-Type ?Ref Ref.Document Proceedings)
(Has-Some ?Ref Ref.Author) (Has-One ?Ref Title-Of)
(Inherits-Year-From-Document ?Ref)
(Has-One ?Ref Ref.Booktitle)
(Same-Values ?Ref Ref.Booktitle
(Compose Title-Of Ref.Document))
(Same-Values ?Ref Ref.Secondary-Title Ref.Booktitle)
(Same-Values ?Ref Ref.Secondary-Author Ref.Editor)
(Same-Values ?Ref Ref.Organization
(Compose Conf.Organization Conference-Of Ref.Document))
(Same-Values ?Ref Ref.Address
(Compose Conf.Address Conference-Of Ref.Document))
(Same-Values ?Ref Ref.Month
(Compose month-of Publication-Date-Of Ref.Document))
(Same-Values ?Ref Ref.Day
(Compose day-of Publication-Date-Of Ref.Document))))
;;; Publication-Reference
(Define-Class Publication-Reference
(?Ref)
"A reference associated with some kind of published document, where
publication and documenthood are interpreted broadly."
:Def
(And (Reference ?Ref)
(Has-One-Of-Type ?Ref Ref.Document Document)
(Has-One ?Ref Title-Of))
:Axiom-Def
(Subclass-Partition Publication-Reference
(Setof Book-Reference Book-Section-Reference Article-Reference
Proceedings-Paper-Reference Thesis-Reference
Technical-Report-Reference Misc-Publication-Reference)))
;;; Publisher-Name
(Define-Class Publisher-Name
(?Name)
"A name of some publisher"
:Axiom-Def
(Exact-Range Name Publisher-Name)
:Constraints
(Biblio-Name ?Name)
:Issues
("see the discussion of AGENT-NAME."))
;;; Reference
(Define-Class Reference
(?Ref)
"A bibliographic reference is a description of some publication that
uniquely identifies it, providing the information needed to retrieve the
associated document. A reference is distinguished from a citation, which occurs
in the body of a document and points to a reference. Note that references
are distinguished from documents as well.
The information associated with a reference is contained in data fields,
which are binary relations (often unary functions).
A reference should at least contain information about the author, title,
and year. (Since there are exceptions, that constraint is associated with a
specialization of this class.) ."
:Def
(Individual-Thing ?Ref)
:Axiom-Def
(Exhaustive-Subclass-Partition Reference
(Setof Publication-Reference Non-Publication-Reference)))
;;; Technical-Manual-Reference
(Define-Class Technical-Manual-Reference
(?Ref)
"A reference to a manual that may accompany a product but is otherwise
unpublished."
:Def
(And (Misc-Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)))
;;; Technical-Report-Reference
(Define-Class Technical-Report-Reference
(?Ref)
:Def
(And (Publication-Reference ?Ref)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)
(Has-One ?Ref Ref.Publisher)
(Same-Values ?Ref Ref.Publisher
(Compose Name Organization-Of))))
;;; Thesis-Reference
(Define-Class Thesis-Reference
(?Ref)
"A reference to a master's or doctoral thesis."
:Def
(And (Publication-Reference ?Ref)
(Value-Type ?Ref Ref.Document Thesis)
(Inherits-Author-From-Document ?Ref)
(Inherits-Title-From-Document ?Ref)
(Inherits-Year-From-Document ?Ref)
(Has-One ?Ref Ref.Publisher)
(Same-Values ?Ref Ref.Publisher
(Compose Name Organization-Of)))
:Axiom-Def
(Subclass-Partition Thesis-Reference
(Setof Doctoral-Thesis-Reference Masters-Thesis-Reference)))
;;; Title
(Define-Class Title
(?X)
"A title is a string naming a publication, a document, or
something analogous. Title strings are distinct from strings naming
agents (books can't talk)."
:Def
(Biblio-Name ?X))
;;; University
;;; ------------------ Relations --------------
(Define-Relation Has-Author-Name
(?Doc ?Name)
"Each author of a document is identified by an author-name.
Although an author can have several pennames, the author only
gets to use one of them for a particular document."
:Def (And (Document ?Doc) (Author-Name ?Name)
(Exists (?Author)
(And (Has-Author ?Doc ?Author)
(Author.Name-Of ?Doc ?Author ?Name)))))
;;; Has-Penname
(Define-Relation Has-Penname
(?Author ?Name)
"An author's pseudonym [Webster]. An author may use several
pseudonyms. Which name is a function of the document.
The penname of an author cannot be his or her real name [denoted
by the function name]; it must be some made-up name."
:Def
(And (Author ?Author) (Biblio-Name ?Name)
(Not (Name ?Author ?Name)))
:Issues
((:See-Also Has-Name Has-Author-Name)))
;;; Publisher.Address
(Define-Relation Publisher.Address
(?Publisher ?City)
"The publisher.address is the name of a city with which a publisher
is associated for document ordering purposes. There may be several
cities associated with a publisher. If the city is well-known,
then just its name is given; otherwise its name and state and sometimes
country are given as the location."
:Def
(And (Publisher ?Publisher) (City-Address ?City)))
;;; Ref.Address
(Define-Relation Ref.Address
(?Ref ?Address)
"The place (e.g., city) where a document is published. Means
different things depending on the reference type."
:Def
(And (Reference ?Ref) (City-Address ?Address)))
;;; Ref.Author
(Define-Relation Ref.Author
(?Ref ?Author-Name)
"Relation between a reference and the name(s) of the
creator(s) of the publication."
:Def
(And (Reference ?Ref) (Author-Name ?Author-Name)))
;;; Ref.Editor
(Define-Relation Ref.Editor
(?Ref ?Editor)
"A reference's editor is the name of the document's editor."
:Axiom-Def
(= Ref.Editor (Compose Name Has-Editor Ref.Document)))
;;; Ref.Keywords
(Define-Relation Ref.Keywords
(?Ref ?Keyword)
"Keywords associated with a reference."
:Def
(And (Reference ?Ref) (Keyword ?Keyword)))
;;; Ref.Labels
(Define-Relation Ref.Labels
(?Ref ?Label)
"Labels associated with a reference."
:Def
(And (Reference ?Ref) (Biblio-Name ?Label)))
;;; Ref.Notes
(Define-Relation Ref.Notes
(?Ref ?Note-String)
"In a reference, the notes field contains a set of strings that is used
to describe all sorts of things."
:Def
(And (Reference ?Ref) (Biblio-Nl-Text ?Note-String)))
;;; Ref.Secondary-Author
(Define-Relation Ref.Secondary-Author
(?Ref ?Editor)
"In a reference, the secondary author field usually names an editor
of some sort who was involved in the production of the work but who
was not a original author."
:Def
(And (Reference ?Ref) (Agent-Name ?Editor)))
;;; Ref.Secondary-Title
(Define-Relation Ref.Secondary-Title
(?Ref ?Title)
"In a reference, the secondary title usually names the book or
serial in which the publication is published."
:Def
(And (Reference ?Ref) (Title ?Title)))
;;; Ref.Series-Editor
(Define-Relation Ref.Series-Editor
(?Ref ?Editor)
"A reference's series editor is the name of a series editor of
the document."
:Axiom-Def
(= Ref.Series-Editor
(Compose Name Has-Series-Editor Ref.Document)))
;;; Ref.Tertiary-Author
(Define-Relation Ref.Tertiary-Author
(?Ref ?Editor)
"Teritiary author of a reference. Beats me what this is."
:Def
(And (Reference ?Ref) (Agent-Name ?Editor)))
;;; Ref.Translator
(Define-Relation Ref.Translator
(?Ref ?Translator)
"A reference's translator is the name of the document's translator."
:Axiom-Def
(= Ref.Translator
(Compose Name Has-Translator Ref.Document)))
;;; ------------------ Functions --------------
;;; Conf.Address
(Define-Function Conf.Address
(?Conference)
:->
?Address
"Conference address."
:Def
(And (Conference ?Conference) (City-Address ?Address)))
;;; Conf.Date
(Define-Function Conf.Date
(?Conference)
:->
?Date
"Conference date."
:Def
(And (Conference ?Conference) (Calendar-Date ?Date)))
;;; Conf.Organization
(Define-Function Conf.Organization
(?Conference)
:->
?Name
"Conference name."
:Def
(And (Conference ?Conference) (Organization ?Name)))
;;; Author.Name-Of
(Define-Function Author.Name-Of
(?Doc ?Author)
:->
?Name
"The name used by an author is a function of the document and the author."
:Def
(And (Document ?Doc) (Author ?Author) (Author-Name ?Name)))
;;; Edition-Of
(Define-Function Edition-Of (?Doc) :-> ?Nth
"Refers to the nth edition of a document."
:Def (And (document ?doc) (Natural ?Nth)))
;;; Ref.Abstract
(Define-Function Ref.Abstract
(?Ref)
:->
?Abstract-String
"In a reference, the abstract field contains a string of natural
language text that is used to describe all sorts of things."
:Def
(And (Reference ?Ref) (Biblio-Nl-Text ?Abstract-String)))
;;; Ref.Booktitle
(Define-Function Ref.Booktitle
(?Ref)
:->
?Title
"The title of the document that is a collection in which a reference
appears. For example, the title-of of a paper in an edited collection
would be the name of the paper, and the ref.booktitle would be the name
of the edited book."
:Def
(And (Reference ?Ref) (Title ?Title)))
;;; Ref.Day
(Define-Function Ref.Day
(?Ref)
:->
?Day
"In a reference, the day of the month in which a publication is published.
Useful for conference proceedings, personal communications."
:Def
(And
(Or (Article-Reference ?Ref)
(Personal-Communication-Reference ?Ref))
(Day-Number ?Day)))
;;; Ref.Document
(Define-Function Ref.Document
(?Ref)
:->
?Document
"Function from references to associated documents.
Is only defined on publication-references, since by definition they are the
references associated with documents."
:Def
(And (Publication-Reference ?Ref) (Document ?Document)))
;;; Ref.Edition
(Define-Function Ref.Edition
(?Ref)
:->
?Nth
"Refers to the nth edition of a document."
:Def
(And (Reference ?Ref) (Natural ?Nth))
:Lambda-Body
(Edition-Of (Ref.Document ?Ref)))
;;; Ref.Issue
(Define-Function Ref.Issue
(?Ref)
:->
?Issue-Number
"In a reference, the issue number of a journal or magazine
in which an article occurs."
:Def
(And (Article-Reference ?Ref) (Natural ?Issue-Number)))
;;; Ref.Magazine-Name
(Define-Function Ref.Magazine-Name
(?Ref)
:->
?Name
"Field for name of the magazine in a magazine article reference."
:Def
(And (Magazine-Article-Reference ?Ref) (Title ?Name)))
;;; Ref.Month
(Define-Function Ref.Month
(?Ref)
:->
?Month
"In a reference, the month in which a publication is published.
Useful for magazines, conference proceedings, and technical reports."
:Def
(And (Or (Article-Reference ?Ref) (Technical-Report ?Ref))
(Month-Name ?Month)))
;;; Ref.Newspaper-Name
(Define-Function Ref.Newspaper-Name
(?Ref)
:->
?Name
"Field for name of a newspaper in a newspaper article reference."
:Def
(And (Newspaper-Article-Reference ?Ref) (Title ?Name)))
;;; Ref.Number-Of-Volumes
(Define-Function Ref.Number-Of-Volumes
(?Ref)
:->
?Number
"In a reference, the number of volumes in the associated document."
:Def
(And (Reference ?Ref) (Natural ?Number)))
;;; Ref.Organization
(Define-Function Ref.Organization
(?Ref)
:->
?Address
"The organization that publishes a referenced document.
May be inherited from a conference organization for proceedings."
:Def
(And (Reference ?Ref) (Organization ?Address)))
;;; Ref.Pages
(Define-Function Ref.Pages
(?Ref)
:->
?Page-Range
"In a reference, the pages of an article or analogous subdocument in which a
publication resides. Specified as a sequence of two integers."
:Def
(And
(Or (Book-Section-Reference ?Ref) (Article-Reference ?Ref)
(Proceedings-Paper-Reference ?Ref))
(List ?Page-Range) (Integer (First ?Page-Range))
(Integer (First (Rest ?Page-Range)))))
;;; Ref.Periodical
(Define-Function Ref.Periodical
(?Ref)
:->
?Journal-Title
"Most general relation between a reference and a journal."
:Def
(And (Reference ?Ref) (Title ?Journal-Title)))
;;; Ref.Publisher
(Define-Function Ref.Publisher
(?Ref)
:->
?Publisher-Name
"The publisher field of a reference points to the publisher of
the associated document."
:Def
(And (Reference ?Ref) (Publisher-Name ?Publisher-Name)))
;;; Ref.Report-Number
(Define-Function Ref.Report-Number
(?Ref)
:->
?Identifier
"An alphanumeric identifier that identifies a technical report within a
series sponsored by the publishing institution. For example, STAN-CS-68-118
is the 118th report number of a report written at Stanford in the computer
science department in 1968."
:Def
(And (Technical-Report-Reference ?Ref)
(Biblio-Name ?Identifier)))
;;; Ref.Type-Of-Work
(Define-Function Ref.Type-Of-Work
(?Ref)
:->
?Name
"An identifier of some specialization within the reference type.
For example, technical reports are labeled with types-of-work such as
``technical report'' and ``memo''. Dissertations are specialized by the
level of the associated degree."
:Def
(And
(Or (Thesis-Reference ?Ref)
(Technical-Report-Reference ?Ref)
(Misc-Publication-Reference ?Ref))
(Biblio-Name ?Name)))
;;; Ref.Volume
(Define-Function Ref.Volume
(?Ref)
:->
?Number
"in a reference, the volume number of a journal or magazine
in which an article occurs."
:Def
(And
(Or (Book-Reference ?Ref) (Book-Section-Reference ?Ref)
(Article-Reference ?Ref))
(Natural ?Number)))
;;; Ref.Year
(Define-Function Ref.Year
(?Ref)
:->
?Year
"The year field is a function from a reference to the year
in which the publication was published."
:Def
(And (Reference ?Ref) (Year-Number ?Year)))
;;; ------------------ Instance --------------
;;; ------------------ Axiom --------------
;;; ------------------ Other --------------
(Define-Relation Has-Name
(?x ?Name)
"An author name is the name of an agent used to identify
it as an author. It is not necessarily unique; authors may
go by pseudonyms. A particular name of an author must
be either the author's real name (i.e., her name), or else
it is one of her pennames."
:axiom-def ((=> (author ?x)
(=> (Has-Name ?x ?name)
(And (Biblio-Name ?Name)
(Or (= (Name ?Author) ?Name)
(Has-Penname ?Author ?Name)))))))
(Define-Function Name (?x) :-> ?Name
"Conference name, and the name of a publisher; one per publisher."
:axiom-def ((=> (Conference ?x)
(=> (= (name ?x) ?name)
(Biblio-Name ?Name)))
(=> (Publisher ?x)
(=> (= (name ?x) ?name)
(and (Biblio-Name ?Name))))))
The bibliographic-data ontology defines the terms used for describing bibliographic references. This ontology defines the basic class for reference objects and the types (classes) for the data objects that appear in references, such as authors and titles. Specific databases will use schemata that associate references with various combinations of data objects, usually as fields in a record. This ontology is intended to provide the basic types from which a specific database schema might be defined.
Simple-Time
Frame-Ontology
Kif-Relations
Kif-Sets
Kif-Lists
Kif-Numbers
Kif-Extensions
Kif-Sets
Kif-Lists ...
Kif-Numbers
Kif-Relations ...
Kif-Meta
Kif-Sets
Kif-Lists ...
Slot-Constraint-Sugar
Frame-Ontology ...
Ranges
Frame-Ontology ...
Agents
Slot-Constraint-Sugar ...
Frame-Ontology ...
Frame-Ontology ...
Slot-Constraint-Sugar ...
Documents
Slot-Constraint-Sugar ...
Frame-Ontology ...
Agents ...
Simple-Time ...
No ontologies include Bibliographic-Data.
No ontologies use Bibliographic-Data.
Biblio-Text
Biblio-Name
Author-Name
City-Address
Keyword
Publisher-Name
Title
Biblio-Nl-Text
Conference
Proceedings
Reference
Non-Publication-Reference
Generic-Unpublished-Reference
Personal-Communication-Reference
Publication-Reference
Article-Reference
Journal-Article-Reference
Magazine-Article-Reference
Newspaper-Article-Reference
Book-Publication-Data-Constraint
Book-Reference
Edited-Book-Reference
Book-Section-Reference
Book-Reference ...
Book-Section-Reference
Inherits-Author-From-Document
Artwork-Reference
Book-Reference ...
Cartographic-Map-Reference
Computer-Program-Reference
Multimedia-Document-Reference
Technical-Manual-Reference
Technical-Report-Reference
Thesis-Reference
Doctoral-Thesis-Reference
Masters-Thesis-Reference
Inherits-Publisher-From-Document
Book-Publication-Data-Constraint ...
Inherits-Title-From-Document
Artwork-Reference
Book-Reference ...
Cartographic-Map-Reference
Computer-Program-Reference
Multimedia-Document-Reference
Technical-Manual-Reference
Technical-Report-Reference
Thesis-Reference ...
Inherits-Year-From-Document
Artwork-Reference
Book-Publication-Data-Constraint ...
Cartographic-Map-Reference
Multimedia-Document-Reference
Proceedings-Paper-Reference
Technical-Manual-Reference
Technical-Report-Reference
Thesis-Reference ...
Misc-Publication-Reference
Artwork-Reference
Cartographic-Map-Reference
Computer-Program-Reference
Multimedia-Document-Reference
Technical-Manual-Reference
Proceedings-Paper-Reference
Technical-Report-Reference
Thesis-Reference ...
Has-Author-Name Has-Name Has-Penname Has-Textual-Representation Publisher.Address Ref.Address Ref.Author Ref.Editor Ref.Keywords Ref.Labels Ref.Notes Ref.Secondary-Author Ref.Secondary-Title Ref.Series-Editor Ref.Tertiary-Author Ref.Translator
Author.Name-Of Conf.Address Conf.Date Conf.Organization Conference-Of Edition-Of Name Ref.Abstract Ref.Booktitle Ref.Day Ref.Document Ref.Edition Ref.Issue Ref.Magazine-Name Ref.Month Ref.Newspaper-Name Ref.Number-Of-Volumes Ref.Organization Ref.Pages Ref.Periodical Ref.Publisher Ref.Report-Number Ref.Type-Of-Work Ref.Volume Ref.Year
Article-Reference Artwork-Reference Author-Name Biblio-Name Biblio-Nl-Text Biblio-Text Book-Publication-Data-Constraint Book-Reference Book-Section-Reference Cartographic-Map-Reference City-Address Computer-Program-Reference Conference Doctoral-Thesis-Reference Edited-Book-Reference Generic-Unpublished-Reference Inherits-Author-From-Document Inherits-Publisher-From-Document Inherits-Title-From-Document Inherits-Year-From-Document Journal-Article-Reference Keyword Magazine-Article-Reference Masters-Thesis-Reference Misc-Publication-Reference Multimedia-Document-Reference Newspaper-Article-Reference Non-Publication-Reference Personal-Communication-Reference Proceedings Proceedings-Paper-Reference Publication-Reference Publisher-Name Reference Technical-Manual-Reference Technical-Report-Reference Thesis-Reference Title
All constants that were mentioned were defined.
The following constants are defined in this ontology and augment definitions in an included ontology(s) (this is not an error):
The ontology shows us an indented, hierarchical view of the classes defined. We note that the superclass of Thesis is Document, which doesn't seem as precise as we'd like. We decide to change the definition of Thesis. We do this first by going to it. The edit we're going to perform is to change Thesis's superclass.